
Das Gralis Speech-Korpus
Alexander Just – Arno Wonisch. Aufnahme, Dekodierung, Bearbeitung und Upload von Audiodateien in das Gralis Fix-Korpus.
Beschreibung: Teil 1 Teil 2 Teil 3 Teil 4 Teil 5
Im Zuge einer Aufnahme, Dekodierung in ein gewünschtes Format, Bearbeitung bzw. Optimierung und schließlich Auswertung bzw. Analyse von Audiodateien gilt es mehrere Arbeitsschritte in unterschiedlichen Programmen durchzuführen, die in vorliegender Anleitung in chronologischer Abfolge dargestellt werden.
Aufnahme von Audiodateien. Zur Durchführung dieses ersten Arbeitsschrittes stehen insgesamt zwei Diktiergeräte und ein Audiorecorder zur Verfügung, die Aufnahmen in folgenden Formaten ermöglichen:
- Zwei Diktiergeräte des Typs Olympus WS-100 – Format: wma (eignet sich für Audioanalysen)
- Audiorecorder Edirol R-09 – Format: wav (eignet sich für Audio- aber auch für Spektralanalysen)
- Weiters bedienen wir uns des Programms Skype Recorder, mit dem via Skype geführte Internettelefonate aufgezeichnet werden können, sodass eine Vielzahl der Aufnahmen direkt vom Arbeitsplatz aus getätigt werden.
Dekodierung vom Format wma ins Format mp3 mithilfe des MediaCoder s. Der „MediaCoder” dient ausschließlich dazu, Audiofiles aus einem Format (wma, wav, mp3, ogg) in ein anderes umzuwandeln. Nach der Transformation der gewünschten Audiodatei ins Format wav kann mit der Bearbeitung bzw. Analyse begonnen werden, die in einem ersten Arbeitsschritt im Programm WaveLab vorgenommen wird.
Arbeitsoberfläche des Programms „MediaCoder“
Bearbeitung und Segmentieren von Audiodateien: Das Programm WaveLab. Das von „Steinberg Media Technologies GmbH“ (www.steinberg.de) entwickelte Programm WaveLab dient im Rahmen des Gralis-Speech-Korpus (bestehend aus dem Gralis-Wort-Korpus, dem Gralis-Fix-Korpus und dem Gralis-Frei-Korpus) zur Be- und Verarbeitung der aufgenommenen Audiodateien. Bei der im Rahmen des Projektes „Die Unterschiede zwischen dem Bosnischen/Bosniakischen, Kroatischen und Serbischen“ verwendeten Version handelt es sich um WaveLab 6, das vom Institut für Slawistik der Karl-Franzens-Universität Graz im Jahre 2007 erworben wurde.
Darstellung von Stereotonspuren im Programm „WaveLab“
Segmentieren bzw. Splitten von Audiodateien im Programm WaveLab. Das Splitten erfolgt mittels Markern, wobei der von uns gewählte Marker der gelbe Standardmarker in der dritten Menüleiste von oben ist. In einem ersten Arbeitsschritt werden die zu segmentierenden Einheiten (Sätze, Wörter) durch ein Setzen des „Standardmarkers“ an den entsprechenden Stellen markiert. Sodann ist der in Abb. 3 dargestellte Befehl „Wave in aktivem Fenster“ anzuwählen, der sich auf die gerade geöffnete Arbeitsoberfläche bezieht.
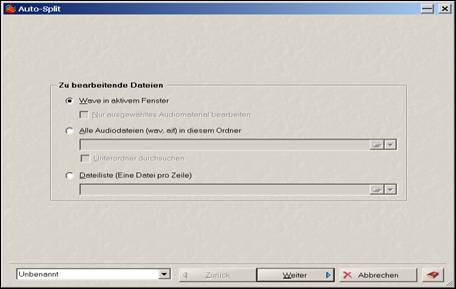
Auswahl „Wave in aktivem Fenster“ im geöffneten Arbeitsfenster
In weiterer Folge ist im nächsten Fenster die Option „Auto-Split entsprechend der Marker“ [sic!] zu aktivieren, damit die Segmentierung gemäß den gesetzten Markern erfolgen kann.
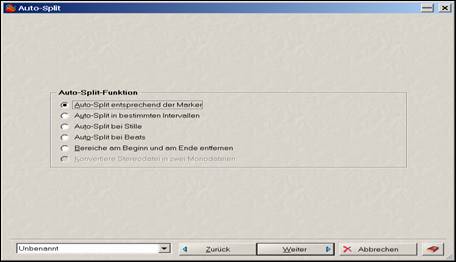
Segmentierung gemäß den Markern
Im Zuge der Bearbeitung der in das Gralis Speech-Korpus hochzuladenden Dateien erwies es sich angesichts der Struktur der Audiofiles als zweckmäßig, zur Segmentierung die vom Programm primär angebotenen Standard-Marker heranzuziehen.
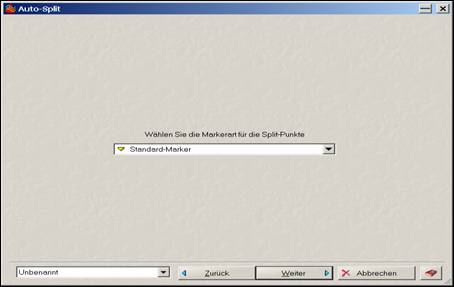
Auto-Split entsprechend den gesetzten (Standard)-Markern
Wichtig ist in weiterer Folge die Wahl des entsprechenden „Zielordners“, in dem die Datei abgespeichert werden soll, wozu in der oben stehenden weißen Zeile dieser auszuwählen ist. Die übrigen Optionen auf dieser Seite sind freizulassen bzw. entsprechend den Voreinstellungen zu übernehmen.
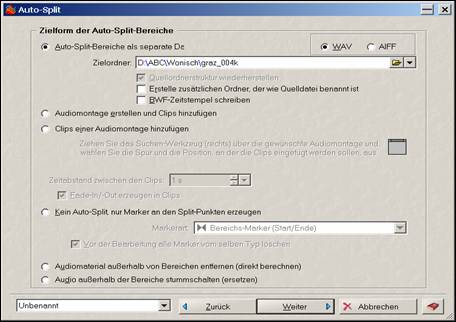
Wahl des Zielordners
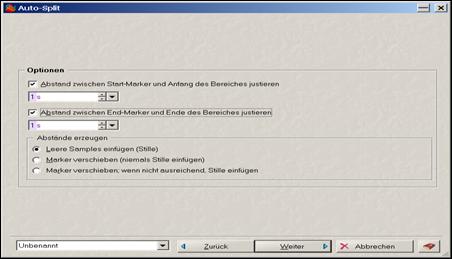
Einfügen von Stille zu Beginn und am Ende der segmentierten Audiodatei
Durch einen Klick auf „Weiter“ gelangt man zu folgendem Fenster in dem sich die Wahl einer Stille von 0 s 500 ms zu Beginn und am Ende einer Datei empfiehlt, wodurch ein Abhören und eine Analyse einer Audiodatei mit einer zeitlichen Verzögerung von einer halben Sekunde vorgenommen werden kann.
Danach sind in ein Fenster die zu den Audiodateien (d. h. Sätzen) gehörenden Benennungen gemäß dem vereinbarten Schema für Chiffren einzufügen, wobei eine Zeile hier für einen Satz steht und der Befehl „Liste (ein Name pro Zeile)“ zu wählen ist.
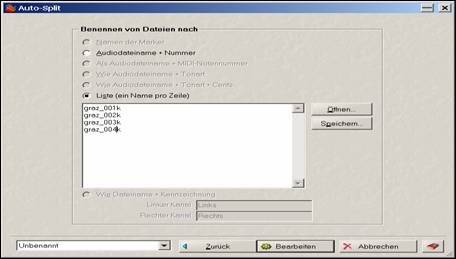
Wahl der Dateinamen
Durch einen abschließenden Klick auf „Bearbeiten“ wird die Segmentierung durchgeführt, woraufhin mit einem abschließenden Speichern sind alle Arbeitsschritte abgeschlossen sind und die segmentierten Einheiten unter den in Abb. 8 gewählten Dateinamen abgespeichert wurden.
Analyse von Audiodateien: Das Programm Praat. Das am Institute of Phonetic Sciences an der Universität Amsterdam von Paul Boersma und David Weenink entwickelte Open-Source-Programm Programm Praat (dt. Übersetzung: „sprechen“) dient zur akustischen Analyse von Audiomaterial im Format wav.
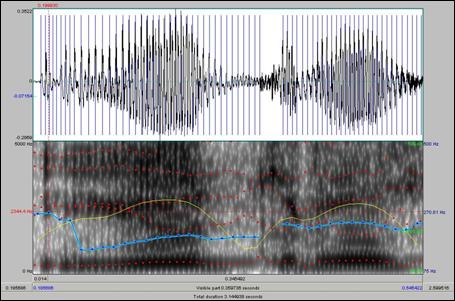
Arbeitsoberfläche des Programms „Praat“
Praat (http://www.fon.hum.uva.nl/praat/) kann in verschiedensten Betriebssystemen (Windows, Linux u. a.) betrieben werden und ermöglicht ein breites Spektrum an phonetischen Analysen, die die Intensität, Intonation, Frequenz, Dauer, Formanten und andere artikulatorische Synthesen umfassen. Daneben können auch Segmentierungen und eine phonetische Transkription vorgenommen werden. Ein Spektrogramm stellt eine zeitlich-spektrale Darstellung des Tonverlaufs dar, wobei auf der Abszisse die Frequenz und auf der Ordinate die Amplitude abgebildet werden. Die im Rahmen des Gralis Speech-Korpus auf Satz- oder Wortebene segmentierten Texte können mithilfe von Praat bis auf die Phonemebene analysiert werden.
Die für das BKS in besonderem Maße interessante Untersuchung der Akzente lässt sich mit dem auf Praat basierenden Programmskript Prosogramm durchführen. Dieses Skript, das daneben auch noch Analysen anderer Art (etwa zur Intonation von Syntagmen und Sätzen) ermöglicht, wurde unter der Leitung von Piet Martens entwickelt und fußt auf einer Reihe von errechneten Parametern, um einer dem menschlichen Ohr entsprechenden Perzeption nahe zu kommen. Für eine akustische Analyse der im Gralis Speech-Korpus enthaltenen Audioaufnahmen ist es erforderlich, zuerst eine Annotation der Dateien in Praat durchzuführen und daneben auch ein TextGrid mit beigefügter Transkription anzulegen. Daraufhin kommt es zum Start des Prosogramms, wobei jeder Satz unter dem gleichen Namen und mit ansteigender Nummerierung abzuspeichern ist (z. B. abc001.wav für die Audiodatei und abc001.TextGrid für das TextGrid mit Transkription). Mit einem abschließenden Betätigen des Installationsfolders werden die Ergebnisse der vom Prosogramm automatisch berechneten akustischen Parameter graphisch dargestellt.
Transkription von Audiodateien: Das Programm Adaba. Dieses Programm stellt das Ergebnis eines sechsjährigen Forschungsprojektes dar und wurde dankenswerterweise vom Leiter dieses Projektes, Rudolf Muhr vom Institut für Germanistik der Universität Graz, zur Verfügung gestellt. Es findet Verwendung bei der Transkription gesprochener, isolierter Wörter, d. h. im Zuge der Bearbeitungsschritte im Rahmen des Gralis Wort-Korpus. Ursprünglich wurde Adaba für einen phonetischen Vergleich von Wörtern entwickelt, die von jeweils einer weiblichen Sprecherin und einem männlichen Sprecher aus Österreich, Deutschland und der Schweiz artikuliert werden. Neben der Audioimplikation verfügt Adaba über eine gemäß dem internationalen phonetischen Alphabet IPA erstellte Transkription sämtlicher Wörter.
Das Gralis Speech-Korpus:
- Branko Tošović. Das Gralis Speech-Korpus
- Olga Lehner. Die technische Entwicklung des Gralis Speech-Korpus
- Sandra Forić. Die Arbeit im Gralis Speech-Korpus
- Maja Midžić. Die Aufnahmeevidenz des Gralis Speech-Korpus
- Alexander Just – Arno Wonisch. Aufnahme, Dekodierung, Bearbeitung und Upload von Audiodateien in das Gralis Fix-Korpus