
Das Gralis Speech-Korpus
Olga Lehner. Die technische Entwicklung des Gralis Speech-Korpus
Beschreibung: Teil 1 Teil 2 Teil 3 Teil 4 Teil 5
In der folgenden Darstellung werden die technischen Aspekte der Entwicklung des Gralis Speech-Korpus erläutert, der der Sammlung, Auswertung und Annotation von Audioaufnahmen dient. Die Korpora werden in einer MySQL-Datenbank verwaltet, die neben den Daten auch den gesamten Entwicklungsprozess abbildet. Die Benutzer- und Administrationsschnittstellen werden, nach Benutzerklassen aufgegliedert, jeweils über ein PHP-Webinterface realisiert.
Lamp. Das Gralis Speech-Korpus wurde auf einem Apache-Web-Server unter dem Betriebssystem Linux generiert, wobei die Information in einer MySQL-Datenbank gespeichert und über ein Webinterface administriert wird. Diese Implikation wie auch die Erstellung von dynamischen Inhalten wurde in PHP programmiert. PHP (rekursives Akronym für „Hypertext Preprocessor“, ursprünglich „Personal Home Page Tools“) ist eine serverseitig interpretierte Skriptsprache mit einer an C bzw. C++ angelehnten Syntax mit breiter Datenbankunterstützung und Internet-Protokolleinbindung. Häufig wird diese Open-Source Kombination (Linux-Apache-MySQL-PHP) als Lamp bezeichnet.
UTF-8-Kodierung. Sowohl auf den HTML-Seiten als auch in der MySQL-Datenbank wird die Unicode UTF-8-Kodierung verwendet (Abk. für das 8-bit Unicode Transformation Format), die bis zu vier Byte unterstützt und auf die sich wie bei allen UTF-Formaten sämtliche 1.114.112 Unicode-Zeichen abbilden lassen. UTF-8 beinhaltet auch die IPA-Symbole (International Phonetic Alphabet), die wir für Akzente, Transkriptionen und Intonationen verwenden. Für die Benutzung reicht es aus, die frei zugängliche Unicodeschrift DoulosSil zu installieren.
Arbeitsumgebung. Die gewählten Arbeitsinstrumente ermöglichen uns, ein eigenes Administrationssystem und eine bequeme Arbeitsumgebung für die am Projekt mitarbeitenden Personen zu schaffen und auf eventuell auftretende Schwierigkeiten, neue Bedürfnisse und Ideen flexibel reagieren zu können.
Die Benutzer des Programms sind auf Gruppen mit verschiedenen Aufgaben und Zugriffsrechten aufgeteilt: Administrator, Mitarbeiter/In, Studierende und ExpertInnen.
Jede(r) Mitarbeiter/In hat eine eigene Arbeitsschnittstelle, wo ihr/ihm die volle Information über die Mitarbeit am Korpus gewährt wird: Anzahl und Liste der eingetragenen Aufnahmeevidenzen, Information über hochgeladene, vollständige und segmentierte wav- und mp3-Audiodateien, über durchgeführte Annotationen der Aufnahmen (Akzente, Transkription und Intonation).
Zu jeder Zeit haben die Mitarbeitenden die Möglichkeit, Aufnahmeevidenzen zu korrigieren, zu löschen, ein unvollendetes Formular fertig zu stellen oder eine neue Aufzeichnung für eine bereits existierende Aufnahme zu ergänzen. Zur Beschleunigung der Eingabe kann man schon existierende Evidenzblätter als Vorlage für den neuen Eintrag heranziehen, was insbesondere bei der Bearbeitung von Sprechenden mit ähnlichen Biographien nützlich ist, wie zum Beispiel bei Schülern einer Klasse, Bewohner eines Ortes etc.
Aus der Gesamtliste können Aufnahmen ausgewählt werden, die sich entweder nur auf das Wort-Korpus (Liste isoliert ausgesprochener Wörter) oder einzig auf das Fix-Korpus beziehen. Die Liste der bearbeiteten Aufnahmeevidenzen kann man nach der laufenden Nummer der Aufzeichnung oder des Sprecher, der Chiffre und dem Datum der Eingabe des Formulars sortieren.
Für die Verwaltung des Korpus erhält der Administrator umfassende Informationen über die bearbeiteten Aufnahmeevidenzen sowie über den jeweiligen Arbeitsfortgang der mitarbeitenden Personen.
phpMyAdmin. Als zusätzliches Werkzeug für die Administration der MySQL - Datenbank verfügt der Administrator über das Programm phpMyAdmin (http://www.phpmyadmin.net), das unter der GNU General Public License lizenziert ist. Dieses Programm stellt ein PHP-basiertes MySQL-Administrierungssystem dar, d. h. es bietet die Möglichkeit, über einen gewöhnlichen Web-Browser eine MySQL-Datenbank zu verwalten (Tabellen und Datensätze anlegen, ändern und löschen, SQL-Befehle ausführen, Datenbankdateien in verschiedenen Formaten exportieren).
Datenbankstruktur. Die Datenbank enthält einige allgemeine Tabellen mit Angaben zur Aufnahmeevidenz und Charakteristik der aufgenommenen Personen: geographische Bezeichnungen (Länder, Regionen, Orte), Muttersprache(n) und Fremdsprachen, Idiome, Mundarten, Nationalität, religiöse Zugehörigkeit, Beruf usw.
Weitere Tabellen enthalten Informationen über die Beschreibung der Audioaufnahme wie Analyse, Typ und Marke des Apparats, der für die Abnahme der Aufzeichnung verwendet wurde, weiters unter welchen Bedingungen die Aufzeichnung stattfand u. Ä. Bei Bedarf fügen die am Korpus mitarbeitenden Personen mit Hilfe des Webinterfaces zu diesen Tabellen neue Angaben ein, die sofort im Aufnahmeevidenzformular zugänglich werden.
Es folgen Tabellen mit Angaben über die in allen Fällen stets anonymen aufgenommenen Personen, eine Tabelle mit der Information zu den Audiodateien der vollen (gesamten) und (in Sätze) segmentierten Aufnahmen.
Das Korpus wird durch mehrere Tabellen dargestellt: Die Thementabelle (Jutro, Na moru, Odlazak na ispit, Moji roditelji usw.), die Satz- und Wörtertabelle, die Tabelle der Wörter mit kanonischem (erwartetem) Akzent, Gralis-Akzentor – mit dem tatsächliche gesprochenen Akzent, Gralis-Transkriptor – Tabelle der transkribierten Sätze und Wörter, Supersegmentarium – Tabelle der Sätze mit Intonation. Durch die Wahl einer solchen Datenbankstruktur erhält man wesentlich umfassendere Möglichkeiten zur Durchführung von Suchabfragen.
Suchabfragen. Wenn man zum Beispiel im Rahmen der einfachen Suche innerhalb des Fix-Korpus einen der Sätze ausgewählt hat, wird die Auswahl nach fünf Kriterien durchgeführt, die einen Sprechenden grundlegend charakterisieren (Geschlecht, Nationalität, Geburtsort und Lebensmittelpunkte, Muttersprache).
In der erweiterten Suche kann man sodann eine Auswahl zu insgesamt über 25 Parametern durchführen. Als Ergebnis der Suche wird die Möglichkeit geboten, den gewählten Satz von verschiedenen Sprechenden anzuhören, die die eingegebenen Kriterien erfüllen (z. B.: weibliche Sprechende mit XXX-Muttersprache).
Durch Klicken auf das Symbol „Tabelle“ in jeder Zeile der Ergebnisstabelle öffnet sich ein neues Fenster, in dem die volle Liste der Sätze inklusive Links auf die entsprechenden Audiodateien, die zum selben Thema gehören und von der gleichen Person gelesen wurden, angezeigt wird.
Man kann die Suche auf annotierte Aufnahmen begrenzen, das heißt auf diejenigen Aufzeichnungen, in denen für jedes Wort der Akzent und die Transkription vermerkt sowie die Intonation markiert wurden. Angesichts der Tatsache, dass die Annotation einen überaus arbeitsintensiven Prozess darstellt, ist es nur schwer möglich, das gesamte Korpus zu annotieren.
Das ebenfalls im Rahmen des Gralis Speech-Korpus entwickelte Wort-Korpus besteht aus Aufnahmen mit isoliert ausgesprochenen Wörtern, die in Wortlisten zusammengefasst wurden. In Ergänzung zur Auswahl nach dem Sprechenden kann eine Suche nach einem Wort, z. B. balon, durchgeführt werden, wobei additional auch eine Eingabe mit Wildcard, z. B. ba*, möglich ist.
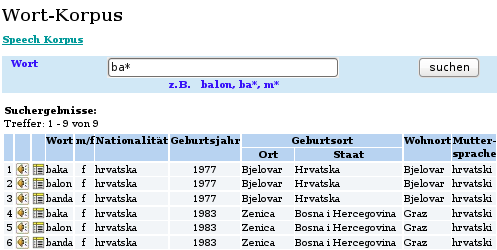
Im Sinne der Erzielung einer größtmöglichen Einheitlichkeit innerhalb des Gralis-Speech-Korpus ist es in absehbarer Zukunft geplant, für das Korpus dieselbe Suchsyntax wie in der IMS Corpus Workbench, auf der das Gralis Text-Korpus fußt, zur Anwendung zu bringen.
Das Gralis Speech-Korpus:
- Branko Tošović. Das Gralis Speech-Korpus
- Olga Lehner. Die technische Entwicklung des Gralis Speech-Korpus
- Sandra Forić. Die Arbeit im Gralis Speech-Korpus
- Maja Midžić. Die Aufnahmeevidenz des Gralis Speech-Korpus
- Alexander Just – Arno Wonisch. Aufnahme, Dekodierung, Bearbeitung und Upload von Audiodateien in das Gralis Fix-Korpus