
Das Gralis Speech-Korpus
Branko Tošović.
Beschreibung: Teil 1 Teil 2 Teil 3 Teil 4 Teil 5
Es handelt sich dabei um eine Online-Sammlung von Audiomaterial (gegenwärtig vorerst nur für das Bosnische/Bosniakische, Kroatische und Serbische), die aus drei Subkorpora – dem Wort-, Fix- und Frei-Korpus – besteht.
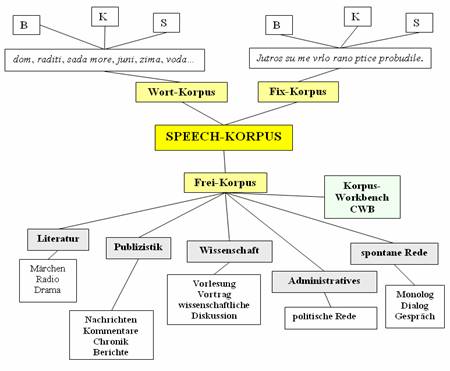
Es sei an dieser Stelle vorab darauf hingewiesen, dass das Wort-Korpus aus Aufnahmen verlesener Wortlisten besteht und es sich beim Fix-Korpus um Aufnahmen kürzerer Texte (der häufig verlesene Text „Jutro“ umfasst 18 Sätze) handelt. Genauere Erklärungen zu diesen Subkorpora (Wort- und Fix-Korpus im Rahmen des Gralis Speech-Korpus) finden sich in weiteren Beiträgen in diesem Kapitel.
Im Rahmen des Speech-Korpus wird auch ein Phonokorpus für die deutsche Sprache in Österreich erstellt ( Oe-Korpus), das dazu dienen soll, mittels einer typologischen Untersuchung die Aussprache in Deutschland und Österreich zu vergleichen und die Übereinstimmungen, Ähnlichkeiten und Unterschiede zwischen nahen Sprachen und ihren Varietäten zu erheben. Das Oe-Koprus wird gemäß einer Vereinbarung zwischen der Firma „Linguatec Sprachtechnologien GmbH“ aus München und dem Leiter des Forschungsprojektes „Die Unterschiede zwischen dem Bosnischen/Bosniakischen, Kroatischen und Serbischen“ entwickelt, wobei den Gegenstand der Zusammenarbeit Aufnahmen österreichischer Sprechender im Sinne einer Erhöhung der Qualität von Spracherkennung für das Deutsche darstellen. Den Output der Aufnahmen bilden Audiodateien im wav-Format mit jeweils 200 Sätzen aus insgesamt 24 unterschiedlichen Skripts, wobei zu jeder aufgenommenen Person wesentliche Metadaten erfasst werden. Die Sprachaufnahmen werden mit dem von Linguatec entwickelten Software-Tool „npcmrec“ vorgenommen und wurden mit Ende Jännner 2008 abgeschlossen.
Das dritte Subkorpus im Rahmen des Gralis Speech-Korpus bildet schließlich das Frei-Korpus, das zur Untersuchung spontan gesprochener Sprache dient. Angesichts der Tatsache, dass für ein solches Korpus keine vergleichbaren Beispiele bestehen (jede sprachliche Äußerung stellt ein Unikat dar und kann über kein semantisches Äquivalent verfügen), müssen Aufnahmen zu vergleichbaren Situationen (z. B. ein Gespräch am Markt, im Restaurant u. Ä.) oder Genres (Dialog, Erzählung, Diskussion, Entgegnung) getätigt werden. Dieses Subkorpus wird außerhalb der Struktur des auf einer MySQL-Datenbank basierenden Speech-Korpus entwickelt und fungiert als Teil des Text-Korpus, dem die Korpussoftware CWB zu Grunde liegt. Gegenwärtig umfasst das Frei-Korpus einzig eine Lebensschilderung, die im Buch Ujak (Tošović 2003) abgedruckt wurde. Eine Suche im Frei-Korpus erfolgt analog zu jener im Text-Korpus, wobei sich die Findstellen wie folgt darstellen:

Am oberen Ende des Suchfensters befindet sich der Verweis auf die Quelle in Form eines Kurztitels (Ujak), auf den ein Pfeil folgt. Klickt man auf den Satz, erhält man die Information zur gesamten bibliographischen Quelle.
Mit einem Klick auf den Satz erhält man weiters auch die Möglichkeit, diesen zu hören. Jeder segmentierte Satz ist mit Audiodateien in zwei Formaten – wav und mp3 – versehen. Die Aufnahme im wav-Format dient für die akustische Analyse und ist (auf Grund des großen Datenumfanges) online nicht zugänglich, sodass in Gralis ausschließlich Aufnahmen im mp3-Format eingestellt werden.
Einen wesentlichen Teil des Frei-Korpus bilden Radio- und TV-Aufnahmen, deren Besonderheit darin liegt, dass sie textuelle, akustische und visuelle Informationen beinhalten. Im Rahmen der Aktivitäten zur Entwicklung des Frei-Korpus wurden z. B. am selben Tag und zur selben Zeit (19.30–20.00 Uhr) die TV-Nachrichten des serbischen, kroatischen und bosnisch-herzegowinischen Fernsehens aufgenommen, die in einem ersten Arbeitsschritt transkribiert wurden. Die gesamte Information (Ton, Bild und Text) wurde sodann in Sätze segmentiert und auf den Server überspielt. Das Ziel lag dabei darin, eine Synchronisation zwischen Text Ton und Bild herzustellen.
Das Gralis Speech-Korpus:
- Branko Tošović. Das Gralis Speech-Korpus
- Olga Lehner. Die technische Entwicklung des Gralis Speech-Korpus
- Sandra Forić. Die Arbeit im Gralis Speech-Korpus
- Maja Midžić. Die Aufnahmeevidenz des Gralis Speech-Korpus
- Alexander Just – Arno Wonisch. Aufnahme, Dekodierung, Bearbeitung und Upload von Audiodateien in das Gralis Fix-Korpus