
Das Gralis Speech-Korpus
Sandra Forić. Die Arbeit im Gralis Speech-Korpus
Beschreibung: Teil 1 Teil 2 Teil 3 Teil 4 Teil 5
Das Gralis Speech-Korpus stellt eine systematische Sammlung ausgewählter Texte und von Audiomaterial für das Bosnische/Bosniakische, Kroatische und Serbische dar und setzt sich aus den Subkorpora Fix-Korpus, Wort-Korpus und Frei-Korpus sowie aus den Applikationen Akzentarium, Transkriptarium und Suprasegmentarium zusammen. Das Korpus-Interface kann in den Sprachen bosnisch/bosniakisch, kroatisch und serbisch abgerufen werden.
Die Arbeit im Gralis Speech-Korpus erfolgt in drei Phasen: 1. Aufnahme von Personen und Ausfüllen einer individuellen Aufnahmeevidenz, 2. Bearbeitung und Einfügung des aufgenommenen Materials und 3. Abfrage und Suche.
Das Gralis Speech-Korpus besteht aus Texten in einer oder mehreren der genannten Sprachen aus sämtlichen Lebensbereichen, Genres und Stilen – von literarisch-künstlerisch über wissenschaftlich bis hin zu Lehrbüchern mit statistischen Angaben –, die ergänzend dazu auch über Audiofiles verfügen, die als Hilfe beim Erlernen von Sprachen und für phonetische Analysen genutzt werden können.
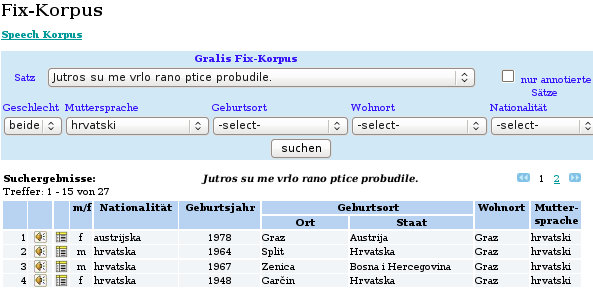
Darstellung eines Suchergebnisses
Die Bearbeitung der Aufnahmen erfolgt in der Rubrik „Audiomaterial“, in der an erster Stelle das zuletzt eingestellte Audiofile mit sämtlichen Angaben und der Aufnahmeevidenz steht. Darunter befinden sich alle Informationen zur aufgenommenen Person, die aus Gründen der Datenanonymität allesamt unter einer Chiffre dargestellt werden. Alle eingegebenen Daten können zu jedem beliebigen Zeitpunkt bearbeitet und gelöscht werden, wobei jedes Login mit einer Datumsangabe versehen ist.
Unter „Status“ erscheint die Anzahl der Aufnahmen, die von einer mitarbeitenden Person angefertigt wurden. Man sieht zudem auch, welche Aufnahmen noch nicht fertig bearbeitet wurden und welche Angaben gemäß Aufnahmeevidenz noch einzutragen sind.

Die Menüführung der Aufnahmeevidenz
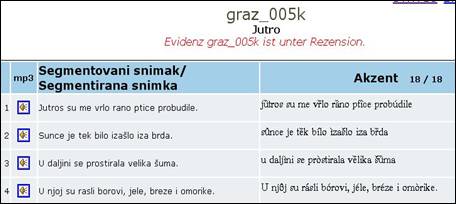
Ein Verzeichnis sämtlicher Angaben ist über das Fix- und über das Wort-Korpus abrufbar, wobei man bei Anwahl des Fix-Korpus eine Liste der bestehenden Texte Jutro, Na obali und Moja prijateljica erhält, die auf Satzebene segmentiert wurden, während das Wort-Korpus eine Liste mit 99 Wörtern enthält.
Die Segmente werden in den Formaten wav und mp3 in das Korpus eingespeist, wobei mp3 für einen schnelleren Download dient und wav alle für eine Spektralanalyse erforderliche Frequenzhöhen beibehält.
In unten stehender Tabelle sind alle Angaben zu den einzelnen zu analysierenden Segmenten beinhaltet. Mit einem Klick auf den Eintrag „Šifra“ öffnet sich die Aufnahmeevidenz, in der die Angabe der Stadt den Aufnahmeort, die dreistellige Nummer die fortlaufende Zahl der aufgenommenen Person und der Kleinbuchstabe am Ende schließlich die jeweilige Muttersprache bezeichnet. Befindet sich hinter der Sprachangabe der Buchstabe w, so ist dies ein Hinweis darauf, dass die Aufnahme Teil des Wort-Korpus ist. Oberhalb des Verzeichnisses befindet sich die Seitenanzahl, wobei die zuletzt in das Korpus eingefügte Audiodatei stets an oberster Stelle der ersten Seite erscheint.
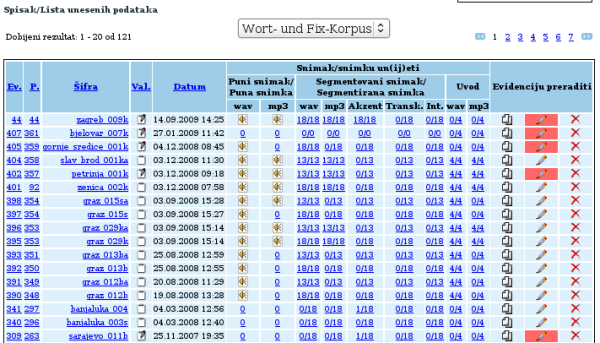
Übersicht über eingetragene Aufnahmeevidenzen und Audiodateien
Die Einführung bzw. Vorstellung der aufgenommenen Person besteht aus der personenbezogenen Chiffre (1), dem Alter (2), Geburtsort (3) und der Muttersprache (4) der befragten Person.
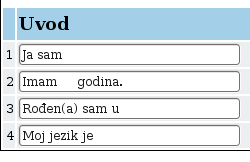
Die Einführung (zu Beginn jeder Aufnahme)
Das bereits erwähnte Frei-Korpus stellt im Gegensatz zum Fix- und Wort-Korpus einen integralen Bestandteil des Gralis Text-Korpus dar, das bislang die Aufnahme zu einer Person umfasst (Ujak 2002).
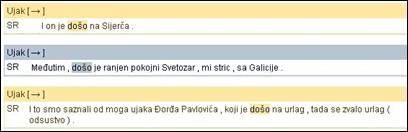
Auszug aus dem Gralis Frei-Korpus
Auf die Aufbereitung und Bearbeitung der Aufnahmen folgt die Analyse der einzelnen Dateien. Dies kann mittels Audio- aber auch durch eine Spektralanalyse mithilfe des Programms Praat und des Skripts Prosogramm geschehen, wobei genanntes Skript für eine eingehende und detaillierte Untersuchung der Intonation und des Akzentes dient. Daneben kann auch noch eine Analyse der Transkription vorgenommen werden.
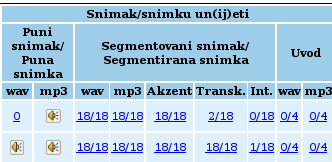
Bearbeitungsstatus von Aufnahmen (Audioformate, Akzentuierung, Transkription, Intonation)
Akzent. Jede mitarbeitende Person legt mittels Audio- oder Spektralanalyse die Akzente der einzelnen Lexeme fest, wobei nach Durchführung einer auf Gehör basierenden Akzentuierung die Dateien unmittelbar nach Abschluss der Arbeiten ins Valorisarium überführt werden, in dem Fachleute eine Beurteilung der Akzente vornehmen. Stimmen die Meinungen dreier ExpertInnen für Akzentologie überein, wird das Wort bzw. eine komplett bearbeitete Datei für die weitere Analyse freigegeben. Sollten die Ansichten divergieren, obliegt die letzte Entscheidung dem Projektleiter, wobei generell darauf hingewiesen sei, dass dieser Arbeitsschritt für alle Beteiligten ein oftmaliges Abhören des Audiomaterials erforderlich macht.
Akzentuierung
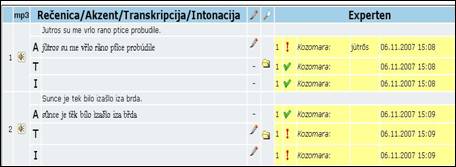
Die Valorisierung stellt die finale Bewertung seitens ausgewiesener Fachleute auf dem Gebiet der Akzentologie dar. Mit ihr endet die Bearbeitung von Aufnahmen im Gralis Speech-Korpus, sodass danach mit der Spektralanalyse begonnen werden kann. Sämtliche von den Fachleuten vorgenommenen Akzentuierungen scheinen dabei neben dem jeweiligen Satz auf. Um einen Text valorisieren zu können, ist in der Rubrik „Audiomaterial“ die entsprechende, individuelle Chiffre einzugeben. In der für die Valorisierung vorgesehen Rubrik befinden sich in der ersten Reihe die akzentuierten Sätze, die nun von den Fachleuten auf ihre Richtigkeit hin zu überprüfen sind. Sämtliche Einträge der ExpertInnen scheinen sodann auf der rechten Seite des überprüften Satzes auf, wobei durch einen Klick auf das Ordnersymbol eventuell falsch gesetzte Akzente eingesehen werden können.
Valorisierung
Intonation. Die Bestimmung der Intonation läuft in zwei Phasen ab. Mittels Audioanalyse wird in einem ersten Arbeitsschritt der Tonverlauf festgelegt, wobei zwischen steigender, gleichbleibender sowie fallender Satzmelodie unterschieden wird und Sprechpausen markiert werden. Daraufhin wird das bereits beschriebene Programmskript Prosogramm geöffnet, von der Darstellung ein Sreenshot angefertigt und in das Korpus eingefügt.

Intonation
Transkription. Die technische Vorgangsweise zur Niederschrift der Transkription entspricht jenen zur Bestimmung der Akzente und der Satzintonation. Als primäres Alphabet dient dazu die so genannte Gralis-Transkription, die eigens für die Bedürfnisse der Sprachen bosnisch/bosniakisch, kroatisch und serbisch entwickelt wurde und später in international übliche Transkriptionsalphabete wie SAMPA oder IPA überführt werden kann.

Transkription
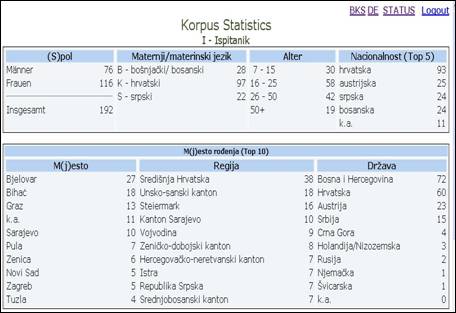
Zur Erlangung eines statistischen Überblickes über die Zahl der aufgenommenen Personen und den aktuellen Umfang des Gralis Speech-Korpus besteht die Möglichkeit, die so genannte „Korpus Statistics“ abzurufen (siehe unten stehende Abbildung) die Parameter wie Geschlecht, Muttersprache, Alter, Nationalität, Geburtsort, -region und -land darstellt.
Korpusstatistiken
Von besonderer Bedeutung für die Bestimmung von Akzenten erweist sich das Akzentarium , in dem durch Eingabe eines Suchbegriffes die jeweiligen Akzentuierungen in den Sprachen bosnisch/bosniakisch, kroatisch, serbisch und serbokroatisch angezeigt werden. Als Quelle für die einzelnen Lexeme dienen dabei Wörterbücher der bosnischen, kroatischen und serbischen Sprache. Mithilfe des Akzentariums wird die Akzentuierung von Wörtern in erheblichem Maße vereinfacht, indem man auf einen Blick die standardologischen Lösungen in Wörterbüchern der jeweiligen Sprachen angezeigt bekommt.

Akzentarium
Suchabfragen im Gralis Speech-Korpus. Das Gralis Speech-Korpus stellt eine Sammlung von Texten und Aufnahmen dar, die auf einfache Weise durchsucht werden können: 1. mittels Wahl des entsprechenden Subkorpus (Text- oder Speech-Korpus) und 2. durch die Wahl von Texten (im Fix-Korpus, Wort-Korpus oder Frei-Korpus). In weiterer Folge kann die Auswahl der Sprache, des Geburtsortes, der Nationalität, des Geschlechts und des Segmentes (d. h. eines Satzes oder Wortes) vorgenommen werden, das zu hören gewünscht wird. Das Korpus bietet eine Reihe an Kombinationsmöglichkeiten im Rahmen der personenbezogenen Angaben, die schließlich gemäß den gewählten Parametern zur Darstellung des gesuchten Audiomaterials führen.
Darstellung von Suchergebnissen
Durch eine Anwahl des Lautsprecher-Symbols  kann die gewählte Audiodatei schließlich angehört werden. Am oberen Rand der Aufnahmeliste erscheint dazu die statistische Angabe (in absoluten Zahlen und prozentuell), wie oft der gesuchte Eintrag mit den entsprechenden Parametern insgesamt im Korpus enthalten ist.
kann die gewählte Audiodatei schließlich angehört werden. Am oberen Rand der Aufnahmeliste erscheint dazu die statistische Angabe (in absoluten Zahlen und prozentuell), wie oft der gesuchte Eintrag mit den entsprechenden Parametern insgesamt im Korpus enthalten ist.
Neben dem Lautsprechersymbol befindet sich eine Darstellung in Form eines Textdokumentes, mithilfe derer alle von einer Person gesprochenen Sätze angehört werden können.

Option zum Anhören aller von einer Person gesprochenen Sätze
Durch die Ausarbeitung der bereits beschriebenen Aufnahmeevidenz als integraler Bestandteil des Gralis Speech-Korpus bietet sich die Möglichkeit, die biographischen Hintergründe jeder einzelnen Person abzurufen, wobei die Anonymität der ProbandInnen gewährleistet ist. Auf Grund der Elastizität des Korpus ist es zu jedem Zeitpunkt möglich, bereits eingetragene Angaben abzuändern und zu löschen, wobei diese ständige Bearbeitungsoption auch auf jedes Audiosegment (Satz und Wort) des Gralis Speech-Korpus zutrifft. Die Analysemöglichkeiten des Audiomaterials umfassen Intonation, Transkription und Akzentuierung und werden durch die zahlreichen Funktionen des Programms Praat und des Skripts Prosogramm wesentlich ausgeweitet.
Das Gralis Speech-Korpus:
- Branko Tošović. Das Gralis Speech-Korpus
- Olga Lehner. Die technische Entwicklung des Gralis Speech-Korpus
- Sandra Forić. Die Arbeit im Gralis Speech-Korpus
- Maja Midžić. Die Aufnahmeevidenz des Gralis Speech-Korpus
- Alexander Just – Arno Wonisch. Aufnahme, Dekodierung, Bearbeitung und Upload von Audiodateien in das Gralis Fix-Korpus